
面试题
自我介绍
您好,我叫XXX,现在在XXX大学读XXX,专业是计算机科学与技术,大学和研究生时间我主要利用课外时间学习了 Java 以及 Spring、MyBatis 等框架 。大学期间参与过一个新闻系统的开发,我在其中主要担任后端开发,这个系统的主要用了SSM框架,研究生期间设计项目飞鱼点评,这个系统的主要用了SpringBoot框架,数据库使用+MySQL+Redis, 平时我喜欢打打羽毛球来放松自己.
反问
面对 HR 或者其他 Level 比较低的面试官时
能不能谈谈你作为一个公司老员工对公司的感受?
能不能问一下,你当时因为什么原因选择加入这家公司的呢或者说这家公司有哪些地方吸引你
我觉得我这次表现的不是太好,你有什么建议或者评价给我吗?
接下来我会有一段空档期,有什么值得注意或者建议学习的吗?
这个岗位为什么还在招人?
大概什么时候能给我回复呢?
如何设计哈希函数
- 易于计算:它应该易于计算,并且不能成为算法本身。
- 统一分布:它应该在哈希表中提供统一分布,不应导致群集。
- 较少的冲突:当元素对映射到相同的哈希值时发生冲突。应该避免这些
解决冲突:
开放地址法:线性探测
链地址法
再哈希法
HashMap多线程情况下会出现什么问题
- 多线程put后可能导致get死循环(put触发多个线程resize,JDK1.7)
- 多线程put的时候可能导致元素丢失(两个线程拿到同一个引用,赋值给.next)
- put非null元素后get出来的却是null(trancefor方法迁移数据时会先将原本索引节点置为null)
1 | if (e != null) { |
评论回复功能设计
评论回复功能设计与总结-Java(两层型)_zukxu的博客-CSDN博客_评论功能设计
悲观锁和乐观锁
悲观锁
总是假设最坏的情况,每次取数据时都认为其他线程会修改,在对共享数据进行操作时先加锁再操作
乐观锁
乐观锁总是假设最好的情况,认为共享资源每次被访问的时候不会出现问题,线程可以不停地执行,无需加锁也无需等待,只是在提交修改的时候去验证对应的资源(也就是数据)是否被其它线程修改了
CAS+版本号
创建线程的方式/多线程的实现方式
- 重写Thread类的run()方法
- 实现Runnable接口传入线程运行
- 实际上Thread类中有一个Runnable target,传入Runnable实际上是覆盖它
- 实现Callable()接口(加了返回值和异常),覆盖call方法,并结合 Future 实现,
4.线程池创建
ThreadLocal原理
ThreadLocal类有一个静态内部类ThreadLocalMap类,键是弱引用的Threadlocal类,值就是保存在ThreadLocal的副本对象,每一个Thread对象都会有一个ThreadLocalMap成员,记录该线程在各个ThreadLocal中保存的副本对象
哈希冲突的解决办法采用了开放地址法,ThreadLocal通常存放的数据量不会特别大,并且使用开放地址法(或叫开放寻址法)相对于拉链法而言节省了存储指针的空间
内存泄漏
如果一个ThreadLocal不存在外部强引用时,Key(ThreadLocal)势必会被GC回收,这样就会导致ThreadLocalMap中key为null, 而value还存在着强引用,只有thead线程退出以后,value的强引用链条才会断掉。
Thread Ref -> Thread -> ThreaLocalMap -> Entry -> value
对应的value在下一次ThreadLocalMap调用set(),get(),remove()的时候会被清除
内存泄漏场景
未关闭的资源类
静态集合引起的内存泄漏
监听器(在释放对象的时候却没有去删除这些监听器)
内部类和外部模块的引用
单例模式
集合里面的对象属性被修改后,再调用remove()方法时不起作用(remove()是根据hashCode进行的,但修改了对象,对象的hashCode会发生改变,但存入集合时对应的hashCode没有变,所以remove()不生效)
适用场景
- 代替显示的参数传递
- 全局存储用户信息(在拦截器的业务中, 获取到保存的用户信息,然后存入ThreadLocal)
- 解决线程安全问题,
1 | 在Spring项目中Dao层中装配的Connection肯定是线程安全的,其解决方案就是采用ThreadLocal方法,当每个请求线程使用Connection的时候, 都会从ThreadLocal获取一次,如果为null,说明没有进行过数据库连接,连接后存入ThreadLocal中,如此一来,每一个请求线程都保存有一份 自己的Connection。 |
子线程获取父线程ThreadLocal
InheritableThreadLocal
可继承的线程变量表,可以让子线程获取到父线程中ThreadLocal的值
线程池运行过程
线程池调用execute—>创建Worker(设置属性thead、firstTask)—>**worker.thread.start()**—>**实际上调用的是worker.run()**—>**线程池的runWorker(worker)**—>worker.firstTask.run()(如果firstTask为null就从等待队列中拉取一个)。
1 | final void runWorker(Worker w) { |
线程的锁
一种是关键字:synchronized,一种是concurrent包下的lock锁
- synchronized
- ReentrantLock
Lock的底层原理
Lock底层实现基于AQS实现,采用线程独占的方式,在硬件层面依赖特殊的CPU指令(CAS)。
简单来说,ReenTrantLock的实现是一种自旋锁,通过循环调用CAS操作来实现加锁。它的性能比较好也是因为避免了使线程进入内核态的阻塞状态。想尽办法避免线程进入内核的阻塞状态是我们去分析和理解锁设计的关键钥匙
AQS
AQS是用CLH队列锁实现的,即:将暂时获取不到锁的线程加入到等待(阻塞)队列中。
AQS是将每一条请求共享资源的被阻塞的等待线程封装成一个CLH锁队列的一个节点,来实现锁的分配
AQS就是基于CLH队列,用volatile修饰共享变量state状态符,线程通过CAS去改变状态符,成功则获取锁成功,失败进入CLH队列,等待被唤醒
AQS底层使用了模板方法模式
AQS底层数据结构是双向链表,锁的存储结构就两个东西 : 双向链表 + “int类型状态”
双亲委派模型好处
避免重复加载 + 避免核心类篡改
1 | 为了不让我们写System类,类加载采用委托机制,这样可以保证爸爸们优先,爸爸们能找到的类,儿子就没有机会加载。而System类是Bootstrap加载器加载的,就算自己重写,也总是使用Java系统提供的System,自己写的System类根本没有机会得到加载。 |
类加载的过程
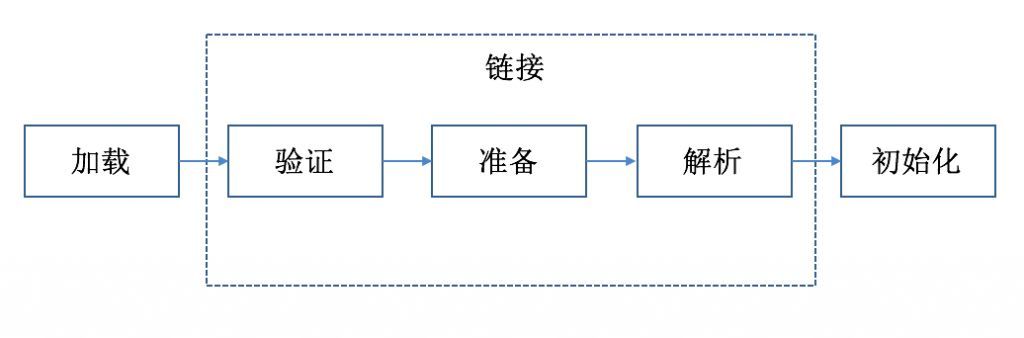
初始化阶段
●初始化阶段就是执行类构造器方法
●此方法不需定义,是javac编译器自动收集类中的所有类变量的赋值动作和静态代码块中的语句合并而来。
●构造器方法中指令按语句在源文件中出现的顺序执行。
●
●若该类具有父类,JVM会保证子类的
●虚拟机必须保证一个类的
垃圾处理器
垃圾回收算法
标记清除算法
好处:
- 实现起来比较简单
缺点:
会有内存碎片,需要维护一个空闲列表
会有停顿操作
效率不是很高
复制算法
好处:
- 没有内存碎片
- 不需要标记清除过程,实现高效,运行高效
缺点:
- 浪费一半的内存空间
标记压缩算法
优点:
- 没有内存碎片
- 不需要浪费一半内存空间
缺点:
- 会有停顿
- 效率没有复制算法高
- 移动对象时,如果对象被引用,还要调整引用的地址
垃圾标记算法
引用计数算法
可达性分析算法
cms垃圾回收的过程
1.初始标记,标记GCRoot能直接关联到的对象,一旦标记完成,恢复运行
2.并发标记:从GCRoot能直接关联到的1对象出发,遍历整个对象图,这个过程不需要暂停用户线程,可以与垃圾收集线程一起并发运行
3.重新标记:有与用户线程和垃圾回收线程并发工作,因此需要重新标记并发期间发生改动的那一部分对象,会需要停顿.
4.并发清除:清理掉之前标记的已经死亡的对象,释放内存空间,也是与用户线程并发.
cms并发标记时.用户线程也需要运行,为保证应用程序有足够内存可用,因此当堆内存使用率达到某一阈值时,便开始进行回收
设计模式
六大原则
- 单一职责原则
- 依赖倒置原则
- 迪米特法则(一个对象应当对其他对象尽可能少的了解。不和陌生人说话。)
- 开闭原则
- 里氏替换原则
- 接口隔离原则
spring中的设计模式
- 工厂模式
- 单例模式
- 适配器模式
- 模板方法
- 观察者模式
- 代理模式
使用过的设计模式
1.策略模式
不同格式的文件使用不同的解压策略
2.责任链模式
登录时判断账号为空,邮箱格式等一系列判断
简单工厂模式是做什么用的
- step1:创建抽象产品类,并为具体产品定义好一个接口;
- step2:创建具体产品类,其通过接口来继承抽象产品类,同时也要定义计划生产的每一个具体产品;
- step3:创建工厂类,其创建的静态方法可以对传入的不同参数做出响应;
- step4:外界使用者就能调用工厂类的静态方法了,通过传入不同参数来创建不同具体产品类的实例。
1 | //step1:创建抽象产品类,定义具体产品的公共接口 |
mq之间的对比
单机吞吐量
topic数量对吞吐量的影响
时效性
可用性
消息可靠性
功能支持

实际使用场景对比:
RabbitMq
- RabbitMQ 的消息应当尽可能的小,并且只用来处理实时且要高可靠性的消息。
- 消费者和生产者的能力尽量对等,否则消息堆积会严重影响 RabbitMQ 的性能。
- 集群部署,使用热备,保证消息的可靠性。
- erlang 语言开发,性能极其好,延时很低;但是不容易深入研究,无法进行扩展,只能等待社区更新。
- 对于中小企业,是最好的选择。
RocketMQ
- Java 开发的,可以深入学习,定制自己公司的MQ,文档相对来说简单一些。
- 接口简单易用,阿里开发大规模应用,值得信赖。
- 可以支撑大规模的 topic 数量,支持复杂 MQ 业务场景
- 社区活跃度一般,万一不维护,需要自己公司研发。所以没有技术实力的不推荐使用。
Kafka
- 应当有一个非常好的运维监控系统,不单单要监控 Kafka 本身,还要监控 Zookeeper。( kafka 强烈的依赖于zookeeper,如果 zookeeper 挂掉了,那么 Kafka 也不行了)
- 对消息顺序不依赖,且不是那么实时的系统。
- 有可能消息重复消费,对消息丢失并不那么敏感的系统。
- 天然适合大数据实时计算以及日志收集
一条Update语句执行过程
具体更新一条记录 UPDATE t_user SET name = ‘xiaolin’ WHERE id = 1; 的流程如下:
- 执行器负责具体执行,会调用存储引擎的接口,通过主键索引树搜索获取 id = 1 这一行记录:
- 如果 id=1 这一行所在的数据页本来就在 buffer pool 中,就直接返回给执行器更新;
- 如果记录不在 buffer pool,将数据页从磁盘读入到 buffer pool,返回记录给执行器。
- 执行器得到聚簇索引记录后,会看一下更新前的记录和更新后的记录是否一样:
- 如果一样的话就不进行后续更新流程;
- 如果不一样的话就把更新前的记录和更新后的记录都当作参数传给 InnoDB 层,让 InnoDB 真正的执行更新记录的操作;
- 开启事务, InnoDB 层更新记录前,首先要记录相应的 undo log,因为这是更新操作,需要把被更新的列的旧值记下来,也就是要生成一条 undo log,undo log 会写入 Buffer Pool 中的 Undo 页面,不过在内存修改该 Undo 页面后,需要记录对应的 redo log。
- InnoDB 层开始更新记录,会先更新内存(同时标记为脏页),然后将记录写到 redo log 里面,这个时候更新就算完成了。为了减少磁盘I/O,不会立即将脏页写入磁盘,后续由后台线程选择一个合适的时机将脏页写入到磁盘。这就是 WAL 技术,MySQL 的写操作并不是立刻写到磁盘上,而是先写 redo 日志,然后在合适的时间再将修改的行数据写到磁盘上。
- 至此,一条记录更新完了。
- 在一条更新语句执行完成后,然后开始记录该语句对应的 binlog,此时记录的 binlog 会被保存到 binlog cache,并没有刷新到硬盘上的 binlog 文件,在事务提交时才会统一将该事务运行过程中的所有 binlog 刷新到硬盘。
- 事务提交(为了方便说明,这里不说组提交的过程,只说两阶段提交):
- prepare 阶段:将 redo log 对应的事务状态设置为 prepare,然后将 redo log 刷新到硬盘;
- commit 阶段:将 binlog 刷新到磁盘,接着调用引擎的提交事务接口,将 redo log 状态设置为 commit(将事务设置为 commit 状态后,刷入到磁盘 redo log 文件);
锁升级
锁升级过程(无锁、偏向锁、轻量级锁、重量级锁)_七月J的博客-CSDN博客_锁升级过程
SpringBoot自动装配
自动装配spring其实也有,springboot在其基础上,利用SPI机制,进行了进一步优化
springboot再启动时会对jar包中的META-INF/spring.factories文件,将其中的配置类型信息加载到Spring容器
没有 Spring Boot 的情况下,如果我们需要引入第三方依赖,需要手动配置,非常麻烦。但是,Spring Boot 中,我们直接引入一个 starter 即可。
引入 starter 之后,我们通过少量注解和一些简单的配置就能使用第三方组件提供的功能了。
自动装配可以简单理解为:通过注解或者一些简单的配置就能在 Spring Boot 的帮助下实现某块功能。
Redis的主从复制怎么实现
全量复制
- slvae向master发送同步请求建立连接,包含自己的replacation id和offest(slave本身也是master,有自己的id和offest)
- master发现不一样,将自己的replacation id和offest发送给slave,slave保存版本信息
- master执行bgsave命令生成RDB文件发送给slave,同时在生成RDB文件时,将生成RDB文件时执行的命令保存到repl_backlog
- RDB清空本地文件,保存RDB文件
- master发送repl_backlog,slave执行repl_backlog中的命令

增量复制
- slave发送replicaof命令发送连接请求,带着自己的replacation id和offest
- master判断id一致,发送continue命令,就将repl_backlog中offset后的命令发送给slave
- slave执行发送过来中的命令

repl_backlog
是一个环形数组,master和slave都在其中有offest
RocketMQ
- NameServer:整个MQ集群提供服务协调与治理,具体就是记录维护Topic、Broker的信息,及监控Broker的运行状态,Name Server是一个几乎无状态节点,可集群部署,节点之间无任何信息同步,相当于注册中心.
- Broker:消息服务器,作为server提供消息核心服务,每个Broker与Name Server集群中的所有节点建立长连接,定时注册Topic信息到所有Name Server;
- Producer:消息生产者,业务的发起方,负责生产消息传输给broker.
- Consumer:消息消费者,业务的处理方,负责从broker获取消息并进行业务逻辑处理
RabbitMQ
- Exchange:交换机的作用就是根据路由规则,将消息转发到对应的队列上。
- Broker:消息服务器,作为server提供消息核心服务
- Channel:信道是建立在真实TCP连接内的虚拟连接
- Routing key:生产者将消息发送到交换机时,会在消息头上携带一个 key,这个 key就是routing key,来指定这个消息的路由规则。
- Routing key:生产者将消息发送到交换机时,会在消息头上携带一个 key,这个 key就是routing key,来指定这个消息的路由规则。
进程和线程的区别
- 进程是资源分配的基本单位,一个程序至少要一个进程,一个进程至少要一个线程
- 进程拥有独立的内存空间,多个线程共享进程的内存和资源
- 线程是cpu调度和分派的基本单位,是能够独立运行的基本单元
- 同一进程的多个线程能并发执行
线程池在项目中的运用
1.使用线程池,将同步方法放入队列中,然后直接返回响应,会极大的提高接口的响应速度
get和post的区别
- GET在浏览器回退时是无害的,而POST会再次提交请求。
- GET产生的URL地址可以被Bookmark,而POST不可以。
- GET请求会被浏览器主动cache,而POST不会,除非手动设置。
- GET请求只能进行url编码,而POST支持多种编码方式。
- GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
- GET请求在URL中传送的参数是有长度限制的,而POST没有。
- 对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
- GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
- GET参数通过URL传递,POST放在Request body中
什么是Mybatics
- MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。
- MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。
- MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。
JVM调优参数
-Xms12g:初始化堆内存大小为12GB。
-Xmx12g:堆内存最大值为12GB 。
-Xmn2400m:新生代大小为2400MB,包括 Eden区与2个Survivor区。
-XX:SurvivorRatio=1:Eden区与一个Survivor区比值为1:1。
-XX:MaxDirectMemorySize=1G:直接内存。报java.lang.OutOfMemoryError: Direct buffer memory 异常可以上调这个值。
-XX:+DisableExplicitGC:禁止运行期显式地调用 System.gc() 来触发fulll GC。
注意: Java RMI的定时GC触发机制可通过配置-Dsun.rmi.dgc.server.gcInterval=86400来控制触发的时间。
-XX:CMSInitiatingOccupancyFraction=60:老年代内存回收阈值,默认值为68。
-XX:ConcGCThreads=4:CMS垃圾回收器并行线程线,推荐值为CPU核心数。
-XX:ParallelGCThreads=8:新生代并行收集器的线程数。
-XX:MaxTenuringThreshold=10:设置垃圾最大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代。对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,增加在年轻代即被回收的概论。
-XX:CMSFullGCsBeforeCompaction=4:指定进行多少次fullGC之后,进行tenured区 内存空间压缩。
-XX:CMSMaxAbortablePrecleanTime=500:当abortable-preclean预清理阶段执行达到这个时间时就会结束。
用spring好处
- 方便解耦,简化开发
- AOP编程支持
- 方便继承各种框架
- 支持IOC
- 声明事务的支持
自定义注解
Java中自定义注解的使用详解_Evan Wang的博客-CSDN博客
Mybatis 工作原理

- 读取 Mybatis 配置文件
mybatis-config.xml 为 Mybatis 的全局配置文件,配置了 Mybatis 的运行环境等信息,例如数据库连接信息。 - 加载映射文件
映射文件即 SQL 映射文件,该文件中配置了操作数据库的 SQL 语句,需要在 MyBatis 配置文件 mybatis-config.xml 中加载。mybatis-config.xml 文件可以加载多个映射文件,每个文件对应数据库中的一张表。 - 构造会话工厂SqlSessionFactory
通过 Mybatis 的环境等配置信息构建会话工厂 SqlSessionFactory。 - 创建会话对象SqlSession
由会话工厂创建 SqlSession 对象,该对象中包含了执行 SQL 语句的所有方法。 - Executor 执行器
Mybatis 底层定义了一个 Executor 接口来操作数据库,它将根据 SqlSession 传递的参数动态地生成需要执行的 SQL 语句,同时负责查询缓存的维护。 - MappedStatement 对象
在 Executor 接口的执行方法中有一个 MappedStatement 类型的参数,该参数是对映射信息的封装,用于存储要映射的 SQL 语句的 id、参数等信息。 - 输入参数映射
输入参数类型可以是 Map、List 等集合类型,也可以是基本数据类型和 POJO 类型。输入参数映射过程类似于 JDBC 对 preparedStatement 对象设置参数的过程。 - 输出结果映射
输出结果类型可以是 Map、 List 等集合类型,也可以是基本数据类型和 POJO 类型。输出结果映射过程类似于 JDBC 对结果集的解析过程
SQL慢查询优化
- sql语句优化,看看有没有用索引
- 可能数据量太大影响查询效率,分库分表
- 升级服务器,读写分离
常用http状态码
1xx
1xx 类状态码属于提示信息,是协议处理中的⼀种中间状态,实际⽤到的⽐较少。
2xx
2xx 类状态码表示服务器成功处理了客户端的请求,也是我们最愿意看到的状态。
「200 OK」是最常⻅的成功状态码,表示⼀切正常。如果是⾮ HEAD 请求,服务器返回的响应头都会有 body
数据。
「204 No Content」也是常⻅的成功状态码,与 200 OK 基本相同,但响应头没有 body 数据。「206 Partial Content」是应⽤于 HTTP 分块下载或断点续传,表示响应返回的 body 数据并不是资源的全部,⽽
是其中的⼀部分,也是服务器处理成功的状态。
3xx
3xx 类状态码表示客户端请求的资源发送了变动,需要客户端⽤新的 URL ᯿新发送请求获取资源,也就是重定
向。
「301 Moved Permanently」表示永久᯿定向,说明请求的资源已经不存在了,需改⽤新的 URL 再次访问。
「302 Found」表示临时᯿定向,说明请求的资源还在,但暂时需要⽤另⼀个 URL 来访问。
301 和 302 都会在响应头⾥使⽤字段 Location ,指明后续要跳转的 URL,浏览器会⾃动᯿定向新的 URL。
「304 Not Modified」不具有跳转的含义,表示资源未修改,᯿定向已存在的缓冲⽂件,也称缓存᯿定向,⽤于缓
存控制。
4xx
4xx 类状态码表示客户端发送的报⽂有误,服务器⽆法处理,也就是错误码的含义。
「400 Bad Request」表示客户端请求的报⽂有错误,但只是个笼统的错误。
「403 Forbidden」表示服务器禁⽌访问资源,并不是客户端的请求出错。
「404 Not Found」表示请求的资源在服务器上不存在或未找到,所以⽆法提供给客户端。
5xx
5xx 类状态码表示客户端请求报⽂正确,但是服务器处理时内部发⽣了错误,属于服务器端的错误码。
「500 Internal Server Error」与 400 类型,是个笼统通⽤的错误码,服务器发⽣了什么错误,我们并不知道。
「501 Not Implemented」表示客户端请求的功能还不⽀持,类似“即将开业,敬请期待”的意思。
「502 Bad Gateway」通常是服务器作为⽹关或代理时返回的错误码,表示服务器⾃身⼯作正常,访问后端服务器
发⽣了错误。
「503 Service Unavailable」表示服务器当前很忙,暂时⽆法响应服务器,类似“⽹络服务正忙,请稍后᯿试”的意
思。
JVM启动参数
Java VM 启动参数详解 - 简书 (jianshu.com)
接口和抽象类区别
- 构造方法
- 抽象类可以有普通成员变量,接口中不行
- 抽象类可以有普通方法,接口不行
- 抽象类可以有静态方法
- 一个类可以实现多个接口,只能继承一个抽象类
- 抽象类中的抽象方法的访问类型可以是public ,protected和默认类型,但接口中的抽象方法只能是public类型的,并且默认即为public abstract类型。
- 抽象类和接口中都可以包含静态成员变量,抽象类中的静态成员变量的访问类型可以任意,但接口中定义的变量只能是public static类型
TCP 粘包半包问题
HTTP协议是有状态还是无状态的?Cookie和Session
HTTP协议是有状态还是无状态的?Cookie和Session__ambition_的博客-CSDN博客_http协议是有状态协议
什么是响应式处理
响应式网站设计(Responsive Web design)是一种网络页面设计布局,页面的设计与开发应当根据用户行为以及设备环境(系统平台、屏幕尺寸、屏幕定向等)进行相应的响应和调整
包装类型的常量池技术了解么?
Java 基本类型的包装类的大部分(Byte,Short,Integer,Long ,Character,Boolean)都实现了常量池技术
为什么要有包装类型?
基本类型有默认值、泛型参数不能是基本类型,数据库中取出的值为null,使用基本类型无法接受
如何创建线程池
ThreadPoolExecutor,Executors
Callable和Runnable的区别
返回值,Callable可以抛出异常
什么是自动拆装箱?原理?
基本类型和包装类型之间的互转。装箱其实就是调用了 包装类的valueOf()方法,拆箱其实就是调用了 xxxValue()方法。
遇到过自动拆箱引发的 NPE 问题吗?
两个常见的场景:
- 数据库的查询结果可能是 null,因为自动拆箱,用基本数据类型接收有 NPE 风险
- 三目运算符使用不当会导致诡异的 NPE 异常
== 和 equals() 的区别
==对于基本类型和引用类型的作用效果是不同的,equals() 不能用于判断基本数据类型的变量,只能用来判断两个对象是否相等。equals() 方法存在两种使用情况:
- 类没有重写 equals()方法 :通过equals()比较该类的两个对象时,等价于通过“==”比较这两个对象,使用的默认是 Object类equals()方法。
- 类重写了 equals()方法 :一般我们都重写 equals()方法来比较两个对象中的属性是否相等;若它们的属性相等,则返回 true(即,认为这两个对象相等)。
Java 反射?反射有什么优点/缺点?你是怎么理解反射的
Mybatis-puls原理
谈谈对 Java 注解的理解,解决了什么问题?
内部类了解吗?匿名内部类了解吗?
1.成员内部类
外部类.内部类 内部类对象 = new 外部类().new 内部类();
2.静态内部类
可以直接向外部类一样实例化
3.方法内部类

- 匿名内部类

创建一个学生选课表和老师授课表
C语言也有类似于JVM、JDK和JRE的概念。
- 编译器(Compiler):编译器是将C语言源代码转换为计算机可以执行的二进制代码的程序。编译器将源代码作为输入并生成可执行文件作为输出。
- 链接器(Linker):链接器将多个二进制文件链接在一起,形成最终的可执行文件。在C语言中,我们需要将程序中使用的函数链接到相应的库文件中。
- C运行时库(C Runtime Library):C运行时库是一组库文件,包含许多函数和程序所需的其他资源。在编译和链接过程中,它们与程序一起使用,并在程序运行时提供支持。
这些概念组成了C语言的基本编译和执行环境。
红黑树
1.根节点为黑色
2.每条路径上的黑节点相同
3.叶节点必须为黑色
4.如果一个节点是红色,那么他的子节点是黑色
Arraylist 和 Vector 、HashMap 和 ConcurrentHashMap
HashMap 的长度为什么是 2 的幂次方
💡 提示:提高运算效率。
线程和进程
进程是程序的一次执行过程,是系统运行程序的基本单位
线程是操作系统可识别的最小执行和调度单位,每个线程有自己的程序计数器、虚拟机栈和本地方法栈
synchronized 关键字的作用,自己是怎么使用的
同步和互斥
单例类双重校验锁
并发编程
JDK1.5之前利用的操作系统的Mutex,JDK1.5之后利用的Monitor对象
对象
对象头
markword
Hash值
GC分代年龄
锁状态标志
偏向线程ID
偏向时间戳
指向线程在栈帧中创建的锁记录的指针
指向Monitor对象的指针
2.类型指针(指向方法区的类)
3.数组长度(可以没有)
实例数据
对象填充
synchronized锁升级
monitor指针指向monitor对象
monitor基于C++的ObjectMonitor类实现.
monitor对象管理一个各种队列控制获取锁的进程
无锁
偏向锁
对象头偏向线程ID为获取到锁的ID
轻量级锁
线程在栈帧创建一个锁记录,使用CAS将对象头的指向栈帧中锁记录的指针设计为自己的,设置成功则获取到锁,失败自旋获取,再失败进入重量级锁
重量级锁
线程进入阻塞状态
synchronized锁不能降级
Lock锁和sychronied区别
- 两者都是可重入锁
- synchronized依赖于JVM而ReentrantLock依赖于API
- Lock锁比sychronied多了一些高级功能
- 可中断锁 lock.lockInterruptibly()
- 可实现公平锁
- 可实现选择性通知
- 利用Condition,线程对象可以注册在指定的
Condition中,从而可以有选择性的进行线程通知 - synchronized相当于整个
Lock对象中只有一个Condition实例
- 利用Condition,线程对象可以注册在指定的
volatile 关键字
1.可见性
禁用CPU缓存,每次去主存取值
2.禁止指令重排序
使用内存屏障
java对象创建
1.类加载检查
2.分配内存
3.初始化零值
4.设置对象头
5.执行init方法
对象的访问定位的两种方式知道吗
句柄池
直接指针
Gcroot
1.虚拟机栈
2.方法区类静态属性
3.方法区静态常量
4.本地方法栈
cms和g1垃圾回收过程
1.初始标记
2.并发标记
3.重新标记 最终标记
4,并发清理 筛选回收
安全点和安全区域
JVM进入特定的位置,记录的信息才能进能暂停用户线程进入GC流程
某一段代码片段之中,引用关系不会发生变化
如何设置跨域访问
1 | 服务端设置响应头Access-Contro-Allow-Origin: "*" |
JSONP
niginx反向代理
