
scrapy爬虫框架
scrapy爬虫框架
创建一个scrapy项目
1 | scrapy startproject 项目名称 |

scrapy.cfg:爬虫项目的配置文件。
init.py:爬虫项目的初始化文件,用来对项目做初始化工作。
items.py:爬虫项目的数据容器文件,用来定义要获取的数据。
pipelines.py:爬虫项目的管道文件,用来对items中的数据进行进一步的加工处理。
settings.py:爬虫项目的设置文件,包含了爬虫项目的设置信息。
middlewares.py:爬虫项目的中间件文件,
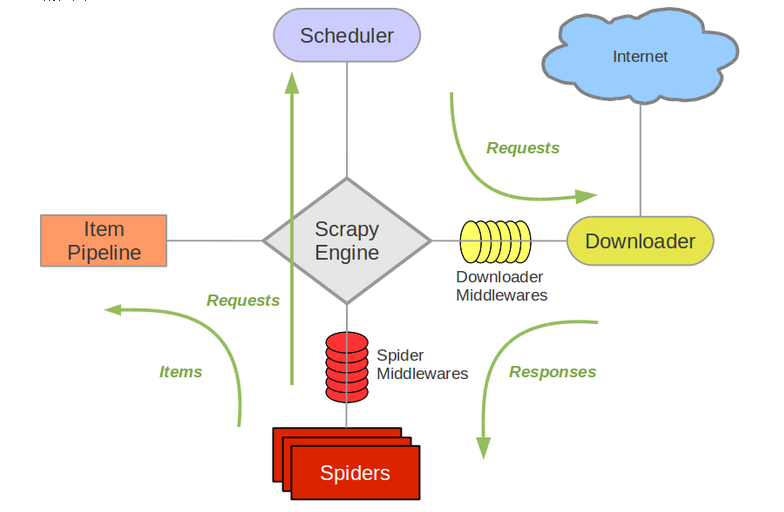
运作流程
1.Engine首先会打开一个起始url,并找到相对应的Spider来处理这个url访问返回的响应结果。
2.在Spider的处理过程中,会将接下来要访问的url包装成Request,Engine会将Request从Spider取出,交给Scheduler进行调度。
3.Engine从Scheduler获取一个Request。
4.Engine将获取到的Request经由下载器中间件(Downloader Middleware)发送给Downloader进行下载并生成相应的Response。
5.Engine从Downloader获取一个Response。
6.Engine将获取的Response经由爬虫中间件(Spider Middleware)发送给相对应的Spider,由Spider来对Response进行解析。在解析过程中,可能会产生两种产物,一种是Item,一种是Request。产生的Request会再次沿着步骤1的流程运行下去,而产生的Item则会进入下一步。
7.Engine从Spider获取一个Item。
8.Engine将获取的Item发送给Item Pipeline进行相对应的存储、清洗等处理。Item Pipeline处理的过程中,同样可能会生成新的Request,这时候生成的Request会直接放入Scheduler中,从步骤3再次执行下去。
创建爬虫应用
- 先切换到爬虫文件夹
1 | scrapy genspider <name> <domain> |

运行流程
1.生成的模板中有一个start_urls参数,这是这个Spider的运行入口,Scrapy会自动的将这个参数中的url发送到Downloader进行下载,并且自动的调用parse方法来处理获得的response。
2.在parse方法处理response的过程中,我们一般会有可能获取两种对象,一个是最终我们从网页上提取的数据,这种数据我们会将其保存为item对象。另一种是我们获取的接下来要访问的url,这一种我们会将其生成为一个Request对象。这两种获得的对象,我们都会使用yield将其返回出去。Scrapy会自动检测对象的类型,如果是item,则会将其发送到item pipeline进行存储等处理,如果是Request对象,则会再次往Downloader发送进行访问。
3.每一个Request对象,都会在生成的时候绑定一个回调函数,用来处理这个请求返回的响应结果。
启动爬虫
方法一
1 | scrapy crawl 爬虫名 |
方法二
在项目文件scrapy.cfg的同级建立main.py文件
1 | from scrapy.cmdline import execute |
1 | from scrapy.crawler import CrawlerProcess |
Item
parse方法一般会返回一个request对象或item对象
Scrapy中,定义了一个专门的通用数据结构:Item。这个Item对象提供了跟字典相似的API,并且有一个非常方便的语法来声明可用的字段。
item对象结构的定义在项目录下的items.py文件中定义。以类的方式定义item对象的各个字段
1 | class MyItem(scrapy.Item): |
1 | //先实例化,然后以字典的方式进行传值 |
注意
如果获取没有声名的字段或给其赋值,将会报错。但可以通过get方法给没有声名的字段设置一个默认值。
实例化item时,可以直接传递一个字典作为参数,但要注意传递字典的key值是已声明的,否则会报错。
定义的item,还可以给其他item所继承。
Pipeline
item对象结构的定义在项目录下的pipelines.py文件中定义
- 在
Spider中返回一个Item后,这个Item将会被发送给Item Pipeline,每个Item Pipeline都是一个Python类,实现了几个简单的方法。其主要有以下几种作用:- 清洗数据
- 验证抓取下来的数据(检查是否含有某些字段)
- 检查去重
- 存储数据
方法
process_item(self, item, spider)
每一个Item Pipeline都会调用这个方法,用来处理Item,返回值为item或dict。这个方法还可以抛出一个DropItem异常,这样将会不再继续调用接下来的Pipeline。
参数item(Item对象或者Dict) 是parse方法传来的。
参数spider(Spider对象) - 抓取这个Item的Spider。
open_spider(self, spider)
这个方法将会在Spider打开时调用。close_spider(self, spider)
这个方法将会在Spider关闭时调用。
启用pipeline:在setting文件中配置,demo是项目名。
1 | ITEM_PIPELINES = { |
Downloader Middleware
作用
更换代理IP,更换Cookies,更换User-Agent,自动重试 等

启用Downloader Middleware :在setting文件中配置
1 | DOWNLOADER_MIDDLEWARES = { |
核心方法
process_request(request, spider)
process_response(request, response, spider)
process_exception(request, exception, spider)
**process_request() **必须返回以下其中之一:一个 None 、一个 Response 对象、一个 Request 对象或 抛出 IgnoreRequest,返回的类型不同,产生的效果也不一样:
如果其返回 None ,Scrapy将继续处理该request,执行其他的中间件的相应方法,直到合适的下载器处理函数(download handler)被调用, 该request被执行(其response被下载)。
如果其返回 Response 对象,Scrapy将不会调用 任何 其他的 process_request() 或 process_exception() 方法,或相应地下载函数; 其将返回该response。 已安装的中间件的 process_response() 方法则会在每个response返回时被调用。
如果其返回 Request 对象,Scrapy则停止调用 process_request方法并重新调度返回的request。当新返回的request被执行后, 相应地中间件链将会根据下载的response被调用。
如果其raise一个 IgnoreRequest 异常,则安装的下载中间件的 process_exception() 方法会被调用。如果没有任何一个方法处理该异常, 则request的errback(Request.errback)方法会被调用。如果没有代码处理抛出的异常, 则该异常被忽略且不记录(不同于其他异常那样)。
process_response(request, response, spider)
DownLoader获得Response之后,会先经过Downloader Middlewares。
- request (Request 对象) – response所对应的request
- response (Response 对象) – 被处理的response
- spider (Spider 对象) – response所对应的spider
process_response() 必须返回以下其中之一: 返回一个 Response 对象、 返回一个 Request 对象或raise一个 IgnoreRequest 异常。
如果其返回一个 Response (可以与传入的response相同,也可以是全新的对象), 该response会被在链中的其他中间件的 process_response() 方法处理。
如果其返回一个 Request 对象,则中间件链停止, 返回的request会被重新调度下载。处理类似于 process_request() 返回request所做的那样。
如果其抛出一个 IgnoreRequest 异常,则调用request的errback(Request.errback)。 如果没有代码处理抛出的异常,则该异常被忽略且不记录(不同于其他异常那样)。
process_exception(request, exception, spider)
当下载处理器(download handler)或 process_request() (下载中间件)抛出异常(包括 IgnoreRequest 异常)时,Scrapy调用 process_exception()
- request (Request 对象) – response所对应的request。
- exception (Exception 对象) – 抛出的异常。
- spider (Spider 对象) – response所对应的spider
process_exception() 也是返回三者中的一个: 返回 None 、 一个 Response 对象、或者一个 Request 对象。
如果其返回 None,Scrapy将会继续处理该异常,接着调用已安装的其他中间件的 process_exception() 方法,直到所有中间件都被调用完毕,则调用默认的异常处理。
如果其返回一个 Response 对象,则已安装的中间件链的 process_response() 方法被调用。Scrapy将不会调用任何其他中间件的 process_exception() 方法。
如果其返回一个 Request 对象, 则返回的request将会被重新调用下载。这将停止中间件的 process_exception() 方法执行,就如返回一个response的那样。 这个是非常有用的,就相当于如果我们失败了可以在这里进行一次失败的重试,例如当我们访问一个网站出现因为频繁爬取被封ip就可以在这里设置增加代理继续访问
